In maart 2019 ontving ik een Onderzoeksgerichte Beurs van de Vlaamse Overheid. Een jaar lang kreeg ik tijd en middelen om me nog verder te verdiepen in het concept van de Algoliteraire Vertellers.
» Read the rest of this entry «Naive Bayes raconte
April 20th, 2019 § 0 comments § permalink
La Gaité Lyrique accueille cette lecture-performance le 20 avril à 15h.

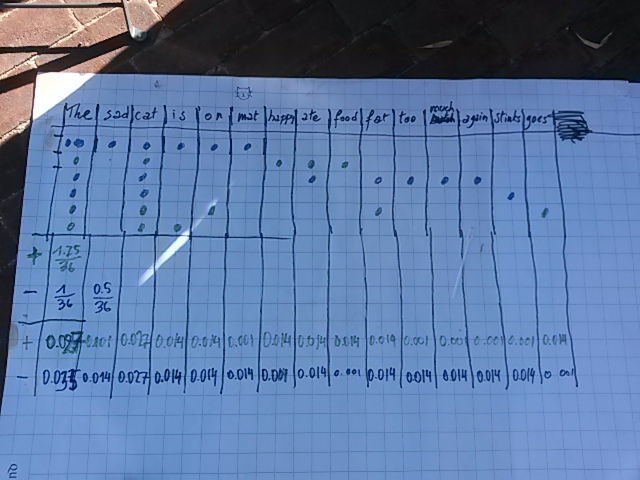
An Mertens expérimente des formes qui dévoilent la personnalité des algorithmes. Pour cette nouvelle création, elle se glisse dans la peau du “classifieur naïf bayésien”, un algorithme très utilisé pour trier les spams de nos boîtes aux lettres, pour analyser les sentiments sur les médias sociaux, mais aussi pour définir si un texte est écrit par une femme ou un homme.
» Read the rest of this entry «Data Workers
March 21st, 2019 § 0 comments § permalink
https://www.algolit.net/index.php/Data_Workers

Data Workers is an exhibition at the Mundaneum from 28th March till 28th April 2019. It shows algoliterary works, stories told from an ’algorithmic storyteller point of view’. The exhibition is a creation by members of Algolit, a group from Brussels involved in artistic research on algorithms and literature. Every month they gather to experiment with F/LOSS code and texts. Some works are by students of Arts² and external participants to the workshop on machine learning and text organised by Algolit in October 2018 in Mundaneum.
» Read the rest of this entry «Algoliterary Game: Naive Bayes
October 17th, 2018 § 0 comments § permalink
The 1st edition of this algoliterary game was developed for the workshop ‘Machine Learning Tools for Literary Creation’, that took place in Mundaneum from 8 till 12 October 2018. It was a collaboration with Gijs de Heij, Arts² Arts Numériques, with the support of Mundaneum and Communauté Française/Arts Numériques.

Algolit
July 10th, 2018 § 0 comments § permalink
 A lot of the ideas on algoliterary creation present here come from the rich exchanges during the monthly meetings of Algolit in Brussels. These meetings are open to anyone.
A lot of the ideas on algoliterary creation present here come from the rich exchanges during the monthly meetings of Algolit in Brussels. These meetings are open to anyone.
Algolit is a project of Constant, a workgroup around i-literature, free code and texts. The group meets regularly following the principles of the Oulipo-meetings: they share work and thoughts and create together, with or without the company of an invitee. Algolit is open to anyone interested in exchanging practises around digital ways of reading and writing. » Read the rest of this entry «
The Algoliterator
June 1st, 2018 § 0 comments § permalink
The Algoliterator is an installation by Gijs De Heij & An Mertens, Algolit, Constant. It was shown in the framework of Public Domain Day 2018 in the public library in Muntpunt, Brussels.


Algologs
April 17th, 2018 § 0 comments § permalink
Dit is een informeel schrijven over Algologs, een publiek programma dat plaatsvond in Varia in Rotterdam op 16 en 17 maart 2018. Het werd georganiseerd door kunstenaars en ontwerpers Manetta Berends en Cristina Cochior.
Naar mijn aanvoelen was het een heerlijk hedendaags conceptueel literair programma. Met dit schrijven geef ik dan ook uiting aan mijn wens dat het niet een one-off event was, maar hopelijk een lange reeks mag worden. Dit artikel beschrijft het avondprogramma. Het is een pleidooi om dit soort avonden literair te noemen. » Read the rest of this entry «
Linear Regression – a forest game
January 31st, 2018 § 0 comments § permalink

A linear regression walk with Natuurgroepering Zoniënwoud, Overijse, June 2017
The forest lends itself as a metaphor for talking about big data. We are interested in the forest because of the amount of trees there are. We enjoy their view, their rustling, the multitude of trunks, fruits, plants. Apart from the forest rangers, few visitors have knowledge of individual trees in the forest, unless they fall outside ‘normality’. Particularly old, thick, large trees, rare specimens can sometimes catch our attention. But the large part of the trees is only interesting for us as a group.
In the same way, companies look at us, users of their technology. When they make up profiles based on our clicks, likes and comments, their focus is not our individual personality, but what we have in common with others, our relationships, our existence in group(s).
Trees are also interconnected via underground networks of mycelium, a phenomenon that covers our entire globe and is referred to as ‘the woodwide web’. Therefore it is tempting to start organising small algorithmic games in the forest based on algorithms used in predictive models.
A first game is an interpretation of the ‘linear regression’. Next to finding a correlation – however subjective, statistically irresponsable and minimal the measurements may be – this exercise also shows the negotiations and compromises that you go through along the way to arrive at usable and measurable data. It is also a very nice way to look at trees in detail.
The story of two sacred trees – a modern fairy tale
March 28th, 2017 § 0 comments § permalink
This story has been written using a Python script and scraped data from the website of Jubelparkmuseum. The story, the code and all the sources are published under a Free Art License: http://artlibre.org.
The main scripts were developed in the framework of DiVersions, a residency of Constant in Musée du Cinquantenaire in December 2016. With a warm thank you to Constant & the Jubelparkmuseum for the tools and the data!
This is what I know about myself.
The description given to me is that of a sacred tree. I am included in the Near East Collection. In case you decide to dress me one day: my height is 75 cm, my width is 87 cm. I have been tagged a relief. I have been categorized with the number o.00271. My body is made of stone. My great grand parents must have lived before -883 / -859. I should be able to find some relatives in Near and Middle East (Asia) as my place of production, and in Nimrud (Asia > Mesopotamia > Assyria) as my place of discovery: . My cultural background is Assyrian. » Read the rest of this entry «
A story from the Algorithmic Forest
March 4th, 2016 § 0 comments § permalink
This image gives an overview of existing techniques for text analysis. By drawing them as a forest, it becomes clear how their application resembles the ecological succession of a forest. In the Brussels process of Forêt de Soignes/Zoniënwoud, the forest came to existence thanks to pioneer species after the last Ice Age. These species can survive on very harsh soil. They grow fast. As they don’t need much to live, produce and reproduce, they are very efficient fertilizers and prepare the soil for other more complex species to come. » Read the rest of this entry «